

Python 라이브러리 시리즈: Pandas 소개
개요 및 설명
Python은 간결하고 읽기 쉬운 문법 덕분에 데이터 과학, 웹 개발, 자동화 등 다양한 분야에서 널리 사용되고 있습니다. Python의 강력한 점 중 하나는 방대한 라이브러리 생태계로, 특정 작업을 더욱 효율적으로 처리할 수 있도록 도와줍니다. 파이썬 라이브러리 시리즈에서는 Python의 주요 라이브러리를 소개하고, 첫 번째 라이브러리로 데이터 분석에 널리 사용되는 Pandas에 대해 알아보겠습니다. Pandas 홈페이지
Pandas란?
Pandas는 데이터 조작 및 분석을 위한 Python 라이브러리로, 주로 구조화된 데이터를 다루는 데 사용됩니다. Pandas는 고성능, 사용이 간편한 데이터 구조와 데이터 분석 도구를 제공합니다. Pandas의 핵심 데이터 구조는 Series와 DataFrame으로, 각각 1차원 및 2차원 데이터를 다루는 데 사용됩니다.
설치하기 전 준비할 것
Pandas를 설치하기 전에 Python과 pip가 설치되어 있는지 확인해야 합니다. 이를 위해 명령어 창에 다음 명령어를 입력해 버전을 확인하세요:
python --version
pip --version만약 설치되어 있지 않다면 Python 공식 사이트에서 Python을 다운로드하고 설치합니다.
Pandas 설치 방법
Pandas를 설치하기 위해서는 Python이 설치되어 있어야 합니다. Python 설치가 완료되었다면, 다음 명령어를 통해 Pandas를 설치할 수 있습니다:
pip install pandas
왜 Pandas를 사용하는가?
Pandas는 데이터 분석과 처리에 있어서 매우 강력하고 유용한 도구입니다. 다음은 Pandas를 사용하는 주요 이유들입니다:
데이터 조작의 용이성:
- Pandas는 데이터를 필터링, 정렬, 집계하는 등의 작업을 간단하게 수행할 수 있는 직관적인 인터페이스를 제공합니다. 예를 들어, 특정 조건에 맞는 데이터만 필터링하거나, 열을 기준으로 데이터를 정렬하는 등의 작업이 매우 쉽습니다.
다양한 데이터 형식 지원:
- Pandas는 CSV, Excel, SQL, JSON 등 다양한 데이터 형식을 읽고 쓸 수 있는 기능을 제공합니다. 이를 통해 다양한 소스에서 데이터를 가져오고, 필요한 형식으로 저장할 수 있습니다.
강력한 데이터 분석 기능:
- 데이터의 요약 통계, 그룹화, 피벗 테이블 등의 기능을 통해 데이터를 쉽게 분석할 수 있습니다. 예를 들어, 데이터의 평균, 합계, 개수 등을 계산할 수 있습니다.
통합성과 호환성:
- Pandas는 NumPy, Matplotlib, Scikit-learn 등 다른 데이터 분석 및 머신러닝 라이브러리와 잘 통합됩니다. 이를 통해 데이터 전처리, 시각화, 머신러닝 모델링 등 다양한 작업을 하나의 워크플로우로 처리할 수 있습니다.
성능:
- Pandas는 대용량 데이터 처리에 있어서도 효율적입니다. 인덱싱, 슬라이싱, 합병 등의 고성능 연산을 지원하여, 복잡한 데이터 조작 작업도 빠르게 수행할 수 있습니다.
커뮤니티와 문서화:
- Pandas는 활발한 커뮤니티와 풍부한 문서화를 갖추고 있어, 다양한 예제와 도움말을 쉽게 찾을 수 있습니다. 이는 문제를 해결하고 새로운 기능을 배우는 데 큰 도움이 됩니다.
주요 Pandas 모듈 설명과 예시
Series: 1차원 데이터 구조로, 리스트와 유사하지만 인덱스를 포함할 수 있습니다.
import pandas as pd
series = pd.Series([1, 2, 3, 4, 5])
print(series)
결과:
PS C:\WORKdev\00Myname\webever\Gemini\Haystack> python .\yahoo.py
0 1
1 2
2 3
3 4
4 5DataFrame: 레이블이 지정된 열과 행이 있는 2차원 표 형식의 데이터 구조입니다. SQL 테이블이나 Excel 스프레드시트와 유사합니다.
import pandas as pd
data = {
'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 24, 35, 32],
'City': ['New York', 'Paris', 'Berlin', 'London']
}
df = pd.DataFrame(data)
print(df)
결과:
PS C:\WORKdev\00Myname\webever\Gemini\Haystack> python .\yahoo.py
Name Age City
0 John 28 New York
1 Anna 24 Paris
2 Peter 35 Berlin
3 Linda 32 London데이터 읽기 및 쓰기
#CSV 파일 읽기
df = pd.read_csv('data.csv')
print(df)
#CSV 파일로 저장
df.to_csv('output.csv', index=False)
#Excel 파일 읽기
df = pd.read_excel('data.xlsx')
print(df)
#Excel 파일로 저장
df.to_excel('output.xlsx', index=False)
데이터 조작하기
#열 선택
names = df['Name']
print(names)
#행 선택
row = df.loc[0] # 첫 번째 행 선택
print(row)
#필터링
filtered_df = df[df['Age'] > 30]
print(filtered_df)
#정렬
sorted_df = df.sort_values(by='Age')
print(sorted_df)
#데이터 추가
df['Country'] = ['USA', 'France', 'Germany', 'UK']
print(df)
#데이터 삭제
df = df.drop(columns=['Country'])
print(df)Data Manipulation: 데이터 프레임을 필터링, 정렬 및 집계하는 방법.
import pandas as pd
# 데이터 프레임 생성
data = {
'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 24, 35, 32],
'City': ['New York', 'Paris', 'Berlin', 'London']
}
df = pd.DataFrame(data)
# 나이가 30 이상인 사람 필터링
df_filtered = df[df['Age'] >= 30]
print(df_filtered)
결과:
PS C:\WORKdev\00Myname\webever\Gemini\Haystack> python .\yahoo.py
Name Age City
2 Peter 35 Berlin
3 Linda 32 London데이터 병합 및 조인 (Merge and Join)
두 개의 데이터 프레임을 특정 열을 기준으로 병합합니다.
import pandas as pd
# 데이터 프레임 생성
df1 = pd.DataFrame({
'EmployeeID': [1, 2, 3, 4],
'Name': ['John', 'Anna', 'Peter', 'Linda']
})
df2 = pd.DataFrame({
'EmployeeID': [3, 4, 5, 6],
'Department': ['HR', 'Finance', 'IT', 'Marketing']
})
# 'EmployeeID'를 기준으로 내부 조인
merged_df = pd.merge(df1, df2, on='EmployeeID', how='inner')
print(merged_df)
결과:
PS C:\WORKdev\00Myname\webever\Gemini\Haystack> python .\yahoo.py
EmployeeID Name Department
0 3 Peter HR
1 4 Linda Finance그룹화 및 집계 (GroupBy and Aggregation)
데이터를 특정 기준으로 그룹화한 후, 각 그룹에 대해 다양한 집계 연산을 수행합니다.
import pandas as pd
# 데이터 프레임 생성
data = {
'Team': ['A', 'A', 'B', 'B', 'C', 'C'],
'Player': ['Alice', 'Bob', 'Charlie', 'David', 'Eva', 'Frank'],
'Score': [10, 15, 10, 20, 5, 15]
}
df = pd.DataFrame(data)
# 팀별로 그룹화하여 점수의 합계와 평균 계산
grouped = df.groupby('Team').agg({'Score': ['sum', 'mean']})
print(grouped)
결과:
PS C:\WORKdev\00Myname\webever\Gemini\Haystack> python .\yahoo.py
Score
sum mean
Team
A 25 12.5
B 30 15.0
C 20 10.0피벗 테이블 (Pivot Table)
데이터를 피벗 테이블 형식으로 변환하여 요약합니다.
import pandas as pd
# 데이터 프레임 생성
data = {
'Date': ['2024-01-01', '2024-01-01', '2024-01-02', '2024-01-02'],
'City': ['New York', 'Los Angeles', 'New York', 'Los Angeles'],
'Sales': [250, 300, 200, 250]
}
df = pd.DataFrame(data)
# 피벗 테이블 생성
pivot_table = df.pivot_table(values='Sales', index='Date', columns='City', aggfunc='sum')
print(pivot_table)
결과:
PS C:\WORKdev\00Myname\webever\Gemini\Haystack> python .\yahoo.py
City Los Angeles New York
Date
2024-01-01 300 250
2024-01-02 250 200결측값 처리 (Handling Missing Data)
결측값을 채우거나 삭제하는 방법을 보여줍니다.
import pandas as pd
import numpy as np
# 데이터 프레임 생성
data = {
'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 24, np.nan, 32],
'City': ['New York', np.nan, 'Berlin', 'London']
}
df = pd.DataFrame(data)
# 결측값을 평균으로 채우기
df['Age'].fillna(df['Age'].mean(), inplace=True)
# 결측값이 있는 행 삭제
df.dropna(subset=['City'], inplace=True)
print(df)
결과:
df['Age'].fillna(df['Age'].mean(), inplace=True)
Name Age City
0 John 28.0 New York
2 Peter 28.0 Berlin
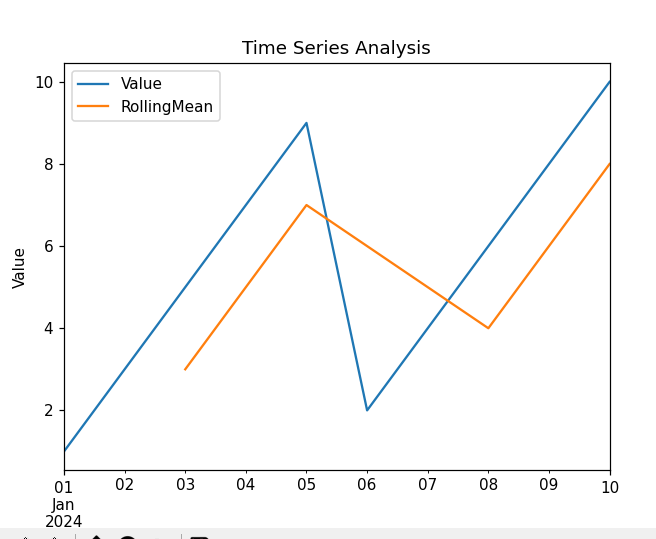
3 Linda 32.0 London시간 시리즈 분석 (Time Series Analysis)
시간 시리즈 데이터를 다루고 시각화합니다.
import pandas as pd
import matplotlib.pyplot as plt
# 날짜 범위 생성
dates = pd.date_range('2024-01-01', periods=10)
# 데이터 프레임 생성
data = {
'Date': dates,
'Value': [1, 3, 5, 7, 9, 2, 4, 6, 8, 10]
}
df = pd.DataFrame(data)
# 'Date'를 인덱스로 설정
df.set_index('Date', inplace=True)
# 이동 평균 계산
df['RollingMean'] = df['Value'].rolling(window=3).mean()
# 시각화
df.plot()
plt.title('Time Series Analysis')
plt.xlabel('Date')
plt.ylabel('Value')
plt.show()
결과:
Pandas를 많이 사용하는 분야
성능, 생산성, 파워가 결합된 판다스는 다음과 같은 영역에서 대화형 데이터 분석을 위한 핵심 도구입니다:
- 금융: 포트폴리오 위험 분석, 트레이딩 전략 시뮬레이션, 재무 데이터에 대한 집계 수행.
- 과학 및 통계: 실험과 관찰에서 얻은 데이터 세트를 정리하고, 조작하고, 모델링합니다.
- 비즈니스: 비즈니스: 주요 비즈니스 메트릭을 보고하고 시각화하며, 추세를 파악합니다.
- 웹 분석: 웹 앱과 서비스의 클릭 스트림, 사용 데이터를 분석합니다.
- 사회 과학: 설문조사, 경제 또는 인구 통계 데이터 세트를 빠르게 로드하고 추세를 분석하세요.
결론
Pandas를 사용하는 것에는 다음과 같은 장점과 단점이 있습니다:
장점:
- 사용이 간편하고 직관적임.
- 풍부한 기능과 유연성 제공.
- 대규모 데이터 처리에 효과적임.
- 다른 데이터 분석 라이브러리와의 통합이 용이함.
단점:
- 메모리 사용량이 많아질 수 있음.
- 매우 큰 데이터셋 처리 시 속도가 느려질 수 있음.
결론적으로, Pandas는 데이터 분석 작업을 간편하게 만들어 주는 강력한 도구입니다. Pandas를 통해 데이터를 효율적으로 다루고 분석할 수 있으며, 이를 통해 보다 깊이 있는 인사이트를 얻을 수 있습니다. Pandas를 처음 사용하는 분들도 쉽게 배울 수 있는 라이브러리이므로, 데이터 작업이 필요하다면 Pandas를 활용해 보세요.




